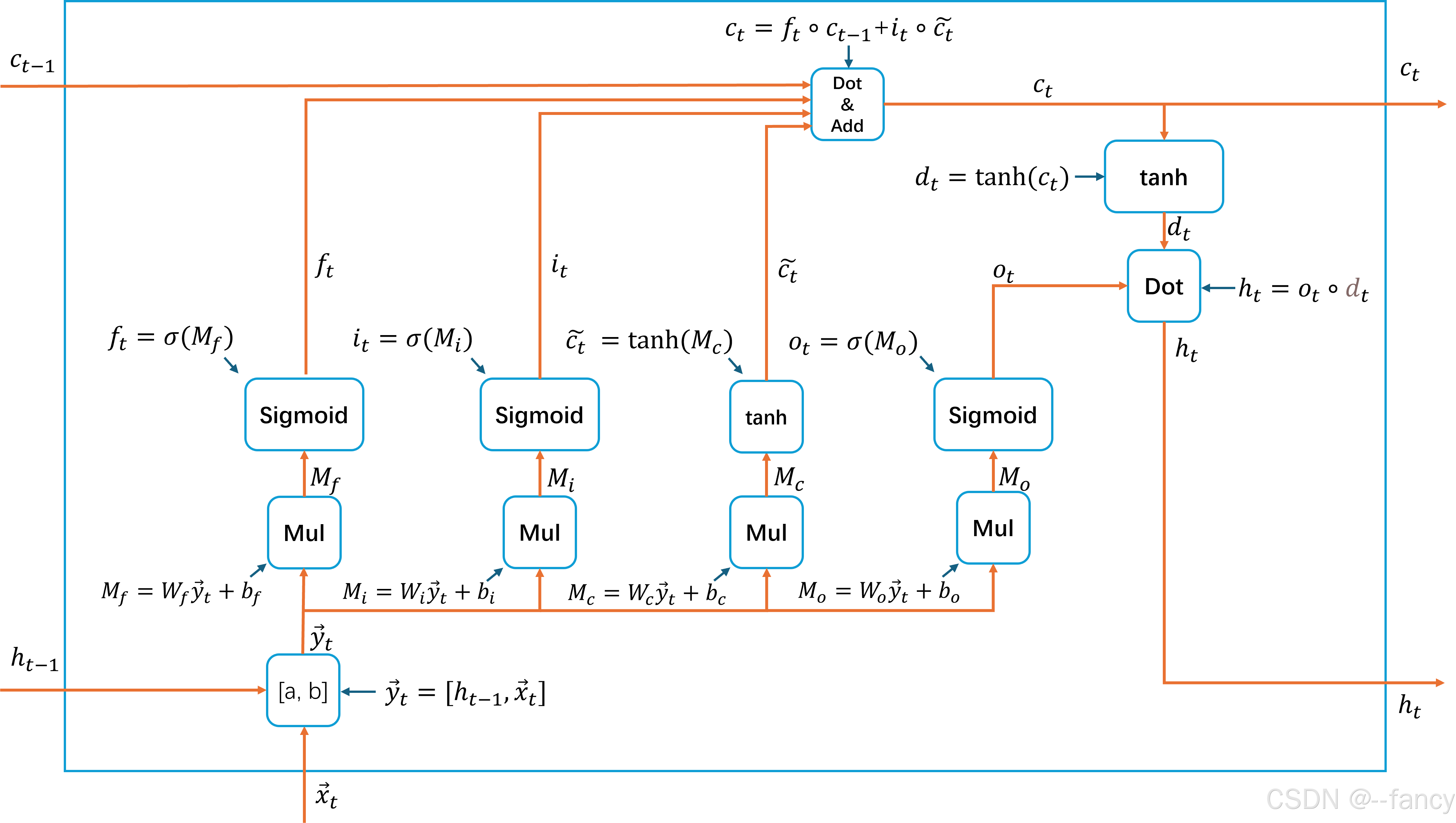
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
| import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv('sh_data.csv')
df = df.iloc[-30:, [2, 5, 3, 4]]
df1 = df[25:28].reset_index(drop=True)
df2 = df1.reset_index(drop=True)
data = df[['open', 'close', 'high', 'low']].values.astype(float)
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
def create_sequences(data, time_step=1):
X, y = [], []
for i in range(len(data) - time_step):
X.append(data[i:(i + time_step)])
y.append(data[i + time_step])
return np.array(X), np.array(y)
time_step = 2
X, y = create_sequences(data, time_step)
X = torch.FloatTensor(X)
y = torch.FloatTensor(y)
class LSTM(nn.Module):
def __init__(self, input_size, hidden_layer_size, output_size):
super(LSTM, self).__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size),
torch.zeros(1, 1, self.hidden_layer_size))
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
input_size = 4
hidden_layer_size = 4
output_size = 4
model = LSTM(input_size=input_size, hidden_layer_size=hidden_layer_size, output_size=output_size)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
seq, labels = X[0], y[0]
optimizer.zero_grad()
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
print(f'Single training loss: {single_loss.item():10.8f}')
model.eval()
with torch.no_grad():
seq = torch.FloatTensor(data[-time_step:])
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
next_day = model(seq).numpy()
next_day = scaler.inverse_transform(next_day.reshape(-1, output_size))
print(f'Predicted features for the next day: open={next_day[0][0]}, close={next_day[0][1]}, high={next_day[0][2]}, low={next_day[0][3]}')
train_predict = []
for seq in X:
with torch.no_grad():
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
train_predict.append(model(seq).numpy())
train_predict = scaler.inverse_transform(np.array(train_predict).reshape(-1, output_size))
actual = scaler.inverse_transform(data)
plt.figure(figsize=(10, 6))
for i, col in enumerate(['open', 'close', 'high', 'low']):
plt.subplot(2, 2, i+1)
plt.plot(actual[:, i], label=f'Actual {col}')
plt.plot(range(time_step, time_step + len(train_predict)), train_predict[:, i], label=f'Train Predict {col}')
plt.legend()
plt.tight_layout()
plt.show()
|